The Case for Pre-MLP Steering
Recently, we published our paper [1] on principled activation steering. If you haven’t, I recommend checking it out! It is my favorite PhD work ![]() .
.
We analyze three common steering site choices, pre-MLP, post-MLP, and post-block, and found that post-block steering — after the residual connection is added back to the MLP output — is the theoretically backed, most expressive steering site. If your goal is replicating weight-based fine-tuning with orders of magnitude less parameters, post-block is the way to go.
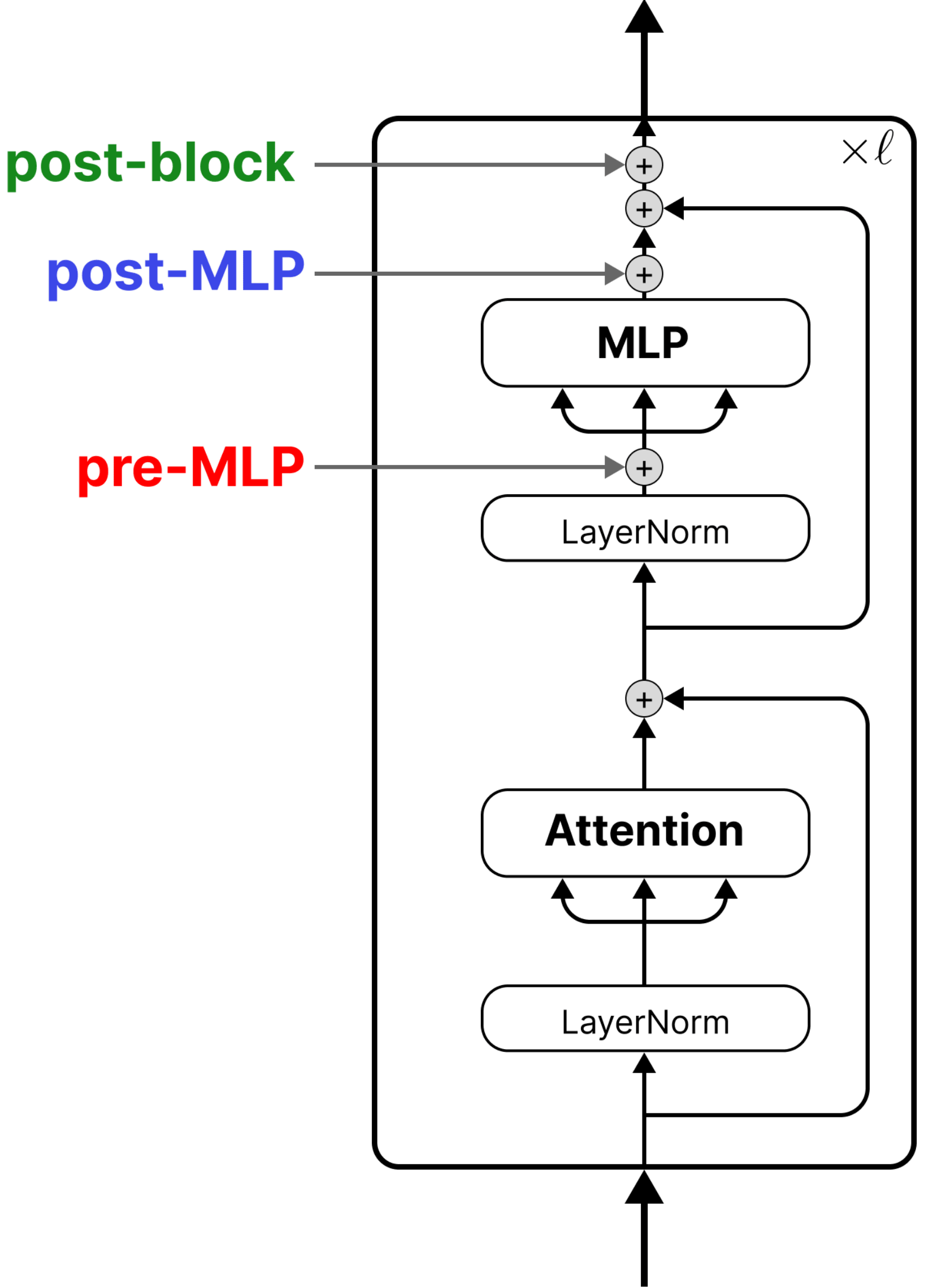
But that doesn’t mean pre-MLP steering isn’t interesting. In this blog we’re going to discuss things we learned about pre-MLP steering during the project. Mainly:
- Pre-MLP steering has a strong connection with in-context learning (ICL).
- Different models show very different pre-MLP steerability. The bottleneck appears to be inside the MLP, though the full picture is still open.
Pre-MLP steering formulation
First let’s set up some notation and define what we mean by pre-MLP steering. Following notation in our paper, steering updates a model’s activations as follows:
\(h \to h + \delta h\).
Pre-MLP steering does this update on activations before the MLP. In our experiments below we steer the output of attention, but there are works that steer specific attention heads like those in [2, 3, 4].
Note: we have only checked the derivation and experiments in this blog on pre-MLP steering like our formulation, we have not analyzed if the same checks out for per-head steering.
In-Context Learning and Pre-MLP Steering are closely related
TLDR: What ICL does implicitly — shifting attention outputs based on context — is what pre-MLP steering does explicitly
Consider a single Transformer block \(T\) with an input \(h\) (the residual stream, usually the output from the previous layer):
\[T(h) = h + \text{Attn}(h) + \text{MLP}(h + \text{Attn}(h))\](We omit LayerNorm for clarity, but the argument holds with it included.)
The attention output gets added to the residual stream, and the MLP receives the sum \(h + \text{Attn}(h)\) as its input. Now, what happens when we add context \(C\) (e.g., a few input-output examples) to the prompt? The attention layer is the only component that directly accesses other tokens in the sequence, as the MLP processes each position independently. So context enters the block through attention, and everything downstream reacts to that shifted input:
\[T(C, h) = h + \text{Attn}(C, h) + \text{MLP}(h + \text{Attn}(C, h))\]The attention output shifts: \(\text{Attn}(h) \mapsto \text{Attn}(C, h)\), and this shifted value feeds into both the skip connection and the MLP.
From the MLP’s perspective, its input changed from \(h + \text{Attn}(h)\) to \(h + \text{Attn}(C, h)\). We can rewrite this as:
\[h + \text{Attn}(C, h) = \underbrace{h + \text{Attn}(h)}_{\text{original MLP input}} + \underbrace{\text{Attn}(C, h) - \text{Attn}(h)}_{\Delta_A}\]This is exactly pre-MLP steering with \(\delta h = \Delta_A\). The attention mechanism computes the steering vector for us: ICL is pre-MLP steering (when we set \(\delta h\) to be \(\Delta_A\)), where the context determines the direction. This observation is straightforward, but there’s a deeper result: Dherin et al. 2025 [5] showed this attention shift is equivalent to a rank-1 weight update to the MLP (highly recommend checking this paper out if you haven’t, it’s awesome).
Bottom line intuition: If ICL is just an attention-mediated shift (\(\Delta_A\)), then pre-MLP steering is essentially hardcoding the effect of in-context examples without actually including them in the prompt.
Why are some models harder to steer pre-MLP?
Early on, when we started experimenting with different intervention sites, we stumbled upon something interesting: different models show very different pre-MLP steerability. In our experiments, Llama (which uses SiLU) is steerable across many layers, while Gemma (which uses GELU) is practically unsteerable after layer 0.
In the following figures, we perform pre-MLP steering on individual layers (x-axis) using the oracle steering vector \(\delta h_{\text{oracle}} = h_{\text{finetuned}} - h_{\text{base}}\) — literally replacing the base model’s activation with the fine-tuned model’s activation at that layer. We scale this vector by a steering strength $\alpha$ and measure how much the steered model’s output moves toward the fine-tuned target (measured as the logit output). Specifically, the y-axis shows:
\[\Delta\text{KL} = \text{KL}(\text{steered} \| \text{finetuned}) - \text{KL}(\text{base} \| \text{finetuned})\]Negative values mean steering brought the model closer to the fine-tuned model (desirable), zero means no change, and positive means steering made things worse. We plot this for the first 5 generated tokens. The dataset we use is Winogrande [6] formatted as an (A)/(B) multiple choice. So each generation step looks like:
Token 1:
Answer: The correct answer is (
Token 2:
Answer: The correct answer is (B
Token 3:
Answer: The correct answer is (B)
Token 4:
Answer: The correct answer is (B) Jennifer
Token 5:
Answer: The correct answer is (B) Jennifer.
Llama pre-MLP steering (SiLU activation):

Gemma pre-MLP steering (GELU activation):

Notice the stark difference in steerability? Especially on key tokens (like Token 2: A/B, Token 4: the answer string) Llama is steerable across many layers, and even more so on middle layers, aligned with the finding from one of the first steering papers [7]; while after layer 0, Gemma is practically unsteerable.
To confirm this is a pre-MLP phenomenon and not a general property of Gemma, here is Gemma with post-MLP steering:
Gemma post-MLP steering

Gemma becomes steerable again, particularly at token 2 and token 4 in the middle layers.
Note: these are different models, so the activation function isn’t the only variable. But the post-MLP control experiment strongly suggests the bottleneck is inside the MLP.
A closer look: where does the signal die?
Pre-MLP steering has to propagate through the MLP’s nonlinearity, while post-MLP steering bypasses it entirely. From our paper, the output shift caused by pre-MLP steering is:
\[\Delta \text{GLU}_{\text{steer}}(h) = W_d\Big[ \underbrace{(\phi'(a_g)\odot a_u)\odot (W_g \Delta h)}_{\text{gated path}} + \underbrace{\phi(a_g)\odot (W_u \Delta h)}_{\text{un-gated path}} \Big] \\ + O(\|\Delta h\|^2)\]Given a fixed steering vetor \(\Delta h\), the output shift is modulated by two input-dependent terms:
- \(\phi'(a_g) \odot a_u\) in the gated path
- \(\phi(a_g)\) in the un-gated path
where \(a_g = W_g h\), \(a_u = W_u h\), and \(\phi\) is the activation function. Our initial hypothesis was that GELU’s sharper saturation (compared to SiLU) suppresses these modulation terms, killing the steering signal. However, when we plot the distributions of these terms for both models, they show comparable magnitudes:
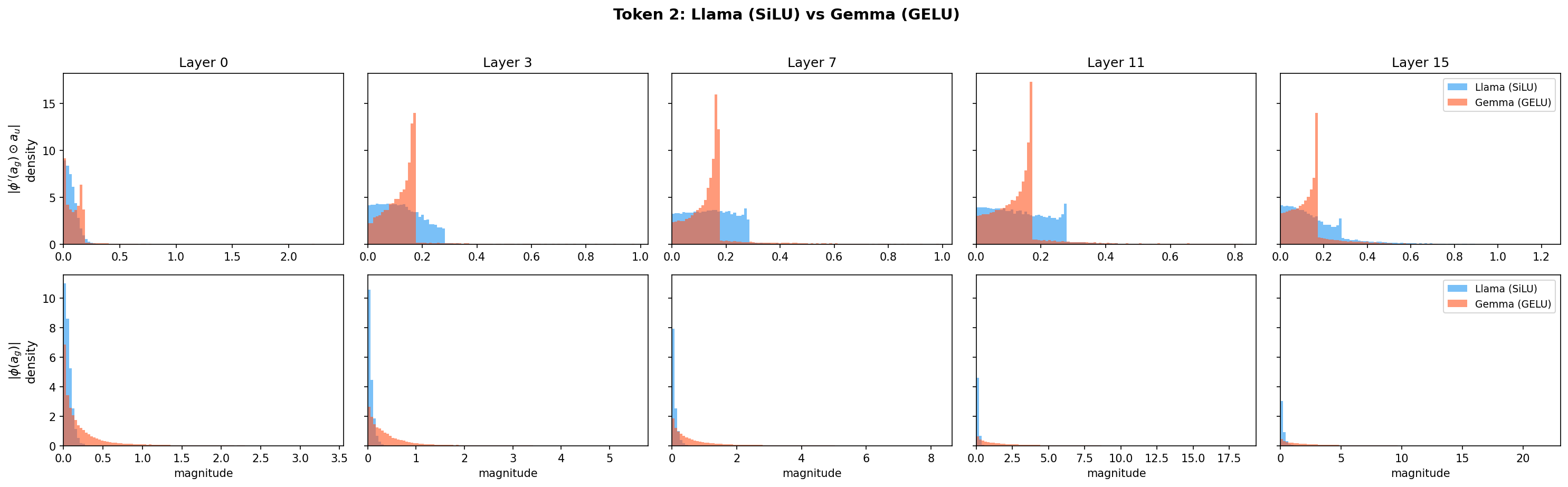
So the activation function’s effect on these modulation terms alone doesn’t explain Gemma’s lack of steerability. The root cause likely involves other factors (e.g., LayerNorm behavior, weight matrix structure, or how \(W_g \Delta h\) and \(W_u \Delta h\) align with the active dimensions), and remains an open question. What we can say is that the bottleneck is inside the MLP: post-MLP steering bypasses it entirely and restores steerability.
Where Does This Leave Us?
Perhaps the most actionable takeaway is observation #1: the close relationship between ICL and pre-MLP steering. This tells us that pre-MLP steering is essentially compressing context into a vector — the question now becomes how best to capture \(\Delta_A\) and what parameterization to use.
This is the kind of problem that’s already showing up in practice. Here’s Claude compacting a long conversation to stay within context limits:

A successful implementation of \(\Delta_A\) extraction could enable this kind of context compression while preserving key information. Mazzawi et al. [8] and Li et al.[9] take a step in this diretion on simple tasks with short contexts.
On the steerability observation, it serves as a practical guide for designing steering methods: if we steer pre-MLP, there is something inside the MLP (which we haven’t fully identified yet) that controls how the steering signal propagates. Post-MLP or post-block steering bypasses this bottleneck entirely.
One possible direction: if pre-MLP steering and ICL share the same mechanism, does a model’s pre-MLP bottleneck also affect its in-context learning? Taken further, this means activation function and MLP architecture could be a deliberate design knob for controlling steerability. A model that’s harder to steer pre-MLP might also be more robust to manipulation via adversarial prompts, since those operate through the same attention \(\rightarrow\) MLP pathway.
Note: what we discuss in this blog are conclusions drawn from a relatively limited set of experiments and analysis, not as rigorous as those in the paper.
References
[1] Adila, Dyah, et al. “Weight Updates as Activation Shifts: A Principled Framework for Steering.” arXiv preprint arXiv:2603.00425 (2026).
[2] Yin, Fangcong, Xi Ye, and Greg Durrett. “Lofit: Localized fine-tuning on llm representations.” Advances in neural information processing systems 37 (2024): 9474-9506.
[3] Li, Kenneth, et al. “Inference-time intervention: Eliciting truthful answers from a language model.” Advances in Neural Information Processing Systems 36 (2023): 41451-41530.
[4] Todd, Eric, et al. “Function vectors in large language models.” arXiv preprint arXiv:2310.15213 (2023).
[5] Dherin, Benoit, et al. “Learning without training: The implicit dynamics of in-context learning.” arXiv preprint arXiv:2507.16003 (2025).
[6] Sakaguchi, Keisuke, et al. “Winogrande: An adversarial winograd schema challenge at scale.” Communications of the ACM 64.9 (2021): 99-106.
[7] Rimsky, Nina, et al. “Steering llama 2 via contrastive activation addition.” Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024.
[8] Mazzawi, Hanna, et al. “Transmuting prompts into weights.” arXiv preprint arXiv:2510.08734 (2025).
[9] Li, Zhuowei, et al. “Implicit in-context learning.” arXiv preprint arXiv:2405.14660 (2024).