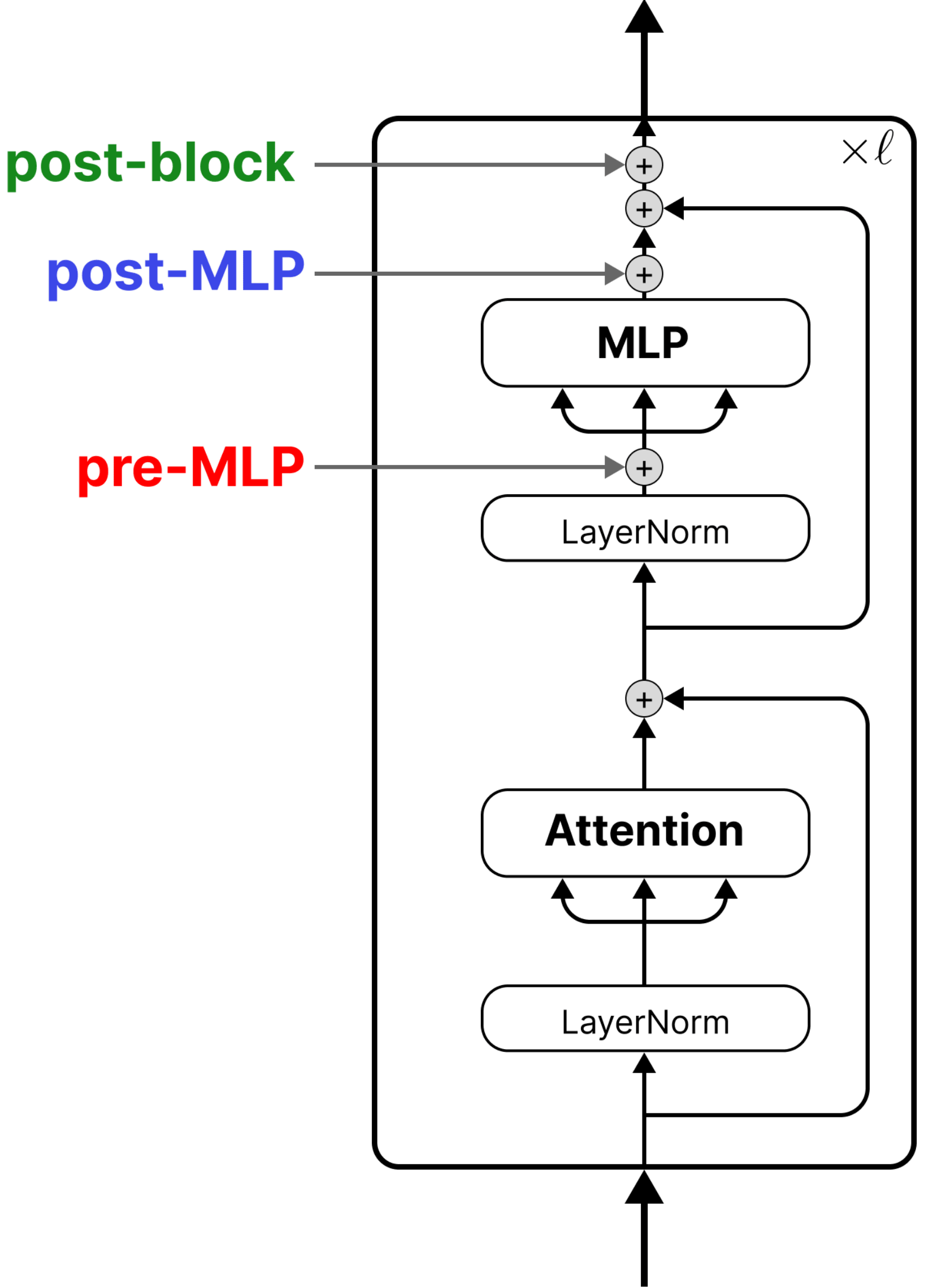
The Case for Pre-MLP Steering
Recently, we published our paper on principled activation steering (if you’re here before checking out the paper, I recommend doing so; it is my favorite work of mine thus far). We found that post-block steering — after the residual connection is added back to the MLP output — is the theoretically backed, most expressive steering site. If your goal is replicating weight-based fine-tuning, post-block is the way to go.
But that doesn’t mean pre-MLP steering isn’t interesting. In fact, it has a neat connection to in-context learning. In this blog we are going to discuss interesting things we learned about pre-MLP steering during the project. Mainly:
- Pre-MLP steering has a strong connection with in-context learning
- The choice of a model’s activation function plays a role into how steerable a model is when we do pre-MLP steering
Note: the stuffs we discuss in this blog are conclusions drawn from a relatively limited set of experiments and analysis, not as rigorous as ones we did in the paper.
Pre-MLP steering formulation
First let’s set up some notation and define what we mean by pre-MLP steering.